下文是对http://preshing.com/20120612/an-introduction-to-lock-free-programming/的翻译,关于无锁编程的入门级介绍。
无锁编程
无锁不是指没有“lock”,而是程序不会“locking up”,无锁的定义可以用下面的图来说明。
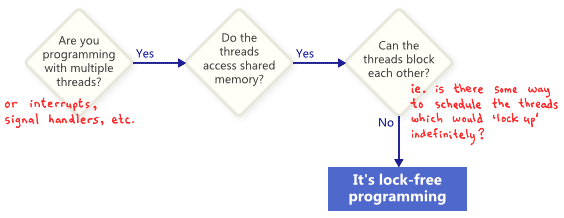
没有“lock”的程序有可能也不是无锁的,比如这个例子,考虑一下如果两个线程同时运行这段程序,有可能循环永远不会结束。
while (X == 0)
{
X = 1 - X;
}
更简明扼要的定义:“In an infinite execution, infinitely often some method call finishes.”,即,只要程序在不断调用无锁操作时,调用完成的次数也在不断增长,在算法上保证程序不会阻塞在无锁操作上。
如果挂起一个线程,不会导致其他线程一直阻塞在无锁操作上。在任务必须在时间限制内完成的情况,比如中断处理或实时系统,无锁操作会非常有用。
如果算法本身具有需要阻塞的操作,比如队列为空时取数据,这并不影响无锁特性。
无锁编程技术
如果想实现无锁编程的非阻塞,可以使用一些技术,比如原子操作、内存屏障、CAS,但是这些技术可能会使情况更糟糕。
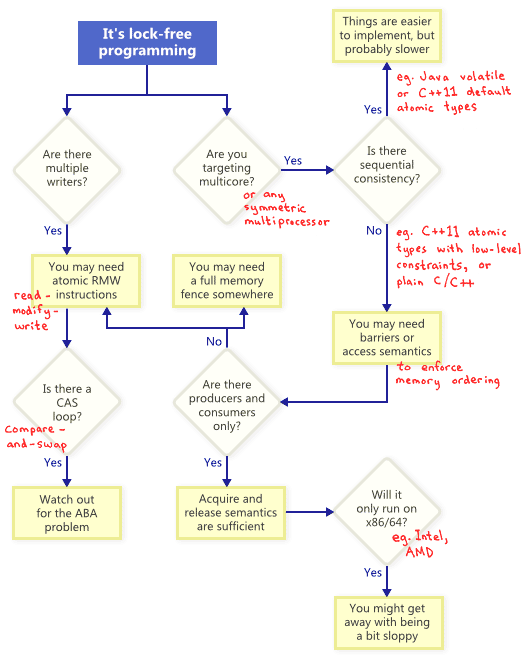
原子Read-Modify-Write操作
原子操作对于内存的操作可以理解为:没有线程会看到原子操作“半完成”,即原子操作要么完成,要么未完成,不会出现完成一半然后切换到其他线程的情况。现今cpu的许多操作都已经是原子操作了,比如对齐的简单类型读写操作。
Read-modify-write(RMW)可以原子地执行更复杂的事务。当无锁算法必须支持多个写者时,多个写者对同一地址的RMW会排队并顺序执行。RMW操作参见lightweight mutex、recrusive mutex和lightweight logging system。
RMW操作的例子包括:Win32的_InterlockedIncrement、iOS的OSAtomicAdd32、C++11的std::atomic<int>::fetch_add,注意C++11原子标准不保证每个平台的实现都是无锁的,需要对平台和工具链有这方面的了解,也可以用std::atomic<>::is_lock_free确认一下。
不同的cpu系列支持RMW的方式可能不同。PowerPC和ARM提供了Load-link/store-conditional指令,你可以自己实现RMW原语,但是一般不这样做。常用的RMW操作已经够用了。如图所示,原子RMW是无锁编程的必要部分,即使对于单cpu系统来说。
Compare-And-Swap Loops
最常见的RMW操作是compare-and-swap(CAS),在Win32中,CAS一般是以一组内联函数的形式提供的,比如_InterlockedCompareExchange。编程时,一般会在循环中重复执行CAS直到成功。一般模式是,先将共享变量的值拷贝到本地变量,执行一些检查工作,然后利用CAS将新的值写入内存。
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
这种循环也是无锁的,因为如果一个线程没有操作成功,表示有其他线程操作成功了,有些架构提供了一种weaker variant of CAS,对于这种CAS,可能上面的循环并不是无锁的。当然,实现CAS循环一定要注意避免ABA问题。
顺序一致性
顺序一致性表示(1)每个线程内部的指令都是按照程序规定的顺序执行的(单线程角度) (2)线程执行的交叉顺序可以任意,但是所有线程看到的程序整体执行顺序一致(整个程序角度)。在顺序一致性的前提下,才能进行内存操作重排,参见内存重排。
实现顺序一致性的一种方式是禁止编译器优化,并强制线程在同一个处理上运行。同一个处理器不会看到内存操作乱序,即使随机切换线程上下文。
对于多处理器环境,一些编程语言对于优化的代码也提供了顺序一致性。比如C++11中的原子类型就具有内存顺序限制。Java中,可以使用关键字volatile。C++11例子如下:
std::atomic<int> X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
因为保证了顺序一致性,所以不会出现r1=r2=0的情况。编译器会在相应的操作后加内存屏障和/或RMW操作。当然,这可能没有直接处理内存顺序高效。
内存排序
如果要在多核(或SMP架构)下进行无锁编程,并且编程环境没有保证顺序一致性,那么就需要考虑如何防止内存重排。
在现今的架构上防止内存重排的技术(防止编译器重排和处理器重排)分为以下三类:
- 轻量sync或fence指令,参加Acquire and Release Semantics;
- full memory fence指令,Lightweight In-Memory Logging;
- 提供acquire或release语义的内存操作。
对于acquire或release语义,参见Acquire and Release Semantics。
不同处理器具有不同的内存模型
比如,PowerPC和ARM处理器可以改变内存存储顺序,但Intel和AMD的x86/64通常不会改变,参见Memory Ordering in Modern Microprocessors, Part II,前者的内存模型称为relaxed memory model。
C++11尝试提供一种标准化方式来编写可移植的无锁代码,但是现在的无锁代码大多还是依赖平台的。在x86/64指令级别,内存读取具有acquire语义,内存写入提供release语义,至少对于非SSE指令和non-write-combined memory来说是这样的。所以,过去经常会发生这种情况,无锁代码在x86/64上可以运行,但是在其他处理器上不能。
想了解处理器如何进行内存重排的硬件细节,参见Is Parallel Programming Hard的附录C。