LinkIn的流式处理框架
Apache Samza是LinkIn开源的分布式流式处理框架,关于流式处理框架,现在最火的是Apache Spark。Samza利用Apache Kafka进行消息传输,同时利用Apache Hadoop YARN提供容错、处理器隔离、安全和资源管理。
Samza的特点
快速开始
hello-samza 是一个独立项目,专门用于帮助samza新手快速构建自己的第一个samza job。
下载源码
git clone git://git.apache.org/samza-hello-samza.git hello-samza
cd hello-samza
启动Grid
Samza grid由YARN、Kafka和Zookeeper三种不同的系统构成。hello-samza提供了一个一键式脚本,可以快速搭建Grid。
bin/grid bootstrap
此脚本会下载、安装、启动Zookeeper、Kafka和YARN,并下载最新的Samza源码并构建。所有的package文件都放在子目录deploy下。
如果提示JAVA_HOME未设置,请设置后再启动。
可以通过YARN UI地址http://localhost:8088验证一下服务是否启动。
构建Samza Job Package
需要为Samza job构建一个package,YARN会用这个package将job部署到grid上。
mvn clean package
mkdir -p deploy/samza
tar -xvf ./target/hello-samza-0.8.0-dist.tar.gz -C deploy/samza
运行Samza job
然后就可以在grid上运行job了
deploy/samza/bin/run-job.sh --config-factory=org.apache.samza.config.factories.PropertiesConfigFactory --config-path=file://$PWD/deploy/samza/config/wikipedia-feed.properties
此job会从维基百科上抓取文章,发送到Kafka topic “wikipedia-raw”。等待一分钟左右就可以启动Kafka的消费者拉取数据了。
deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wikipedia-raw
查看YARN UI(http://localhost:8088)可以看到运行的job。
生成维基百科统计数据
可以再启动另外两个job对wikipedia-raw中的数据进行分析
deploy/samza/bin/run-job.sh --config-factory=org.apache.samza.config.factories.PropertiesConfigFactory --config-path=file://$PWD/deploy/samza/config/wikipedia-parser.properties
deploy/samza/bin/run-job.sh --config-factory=org.apache.samza.config.factories.PropertiesConfigFactory --config-path=file://$PWD/deploy/samza/config/wikipedia-stats.properties
第一个job(wikipedia-parser)会对wikipedia-raw中的数据进行分析,然后将计算的edit的大小信息发送到wikipedia-edits,可以启动consumer查看这些数据:
deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wikipedia-edits
第二个job(wikipedia-stats)会读取topic:wikipedia-edits的数据,并以十分钟为周期对edits数量进行统计,然后将这些数据发送到topic:wikipedia-stats
deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wikipedia-stats
关闭Grid
bin/grid stop all
背景
什么是消息
消息系统是实现近实时计算的一种方法。消息可以被存入消息队列ActiveMQ、RabbitMQ,发布订阅系统(Kestrel、Kafka),日志聚合系统(Flume,Scribe),下游消费者可以消费这些消息,对其进行处理或根据这些消息执行某些action。
假设每次有用户点击网站,就会产生“user viewed page”事件,存入消息系统。消费者可能会做以下事情:
- 存入Hadoop以备以后进行分析
- 统计page view并更新dashboard
- page view失败时发出报警
- 向另一个用户发送邮件
- 对page view与用户信息进行组合,并回发到消息系统
消息系统可以将page view操作与以上这些事情解耦。
什么是流处理
消息系统是一种底层基础架构,存储消息并等待消费者消费。但是在编写producer和consumer时,你会发现很多与处理相关的问题,Samza就是为了解决这些问题。
对于统计的例子(统计page view并更新dashboard),如果运行consumer的机器挂了,统计值丢失,如何恢复?处理程序重启时从何处开始运行?如果消息系统发送了重复的消息或丢失了一条消息?如果想要根据URL分类统计?如果对于一台机器来说计算量太大,如何进行分布式处理?
流处理是对消息系统更高层次的抽象,就是为了解决上述问题。
Samza
Samza具有以下特点:
- 简单的API
回调方式的消息处理接口,与MapReduce类似
- 管理State
Samza会管理流处理器状态的快照和恢复。流处理器重启时,Samza会将其状态恢复到一个一致的快照,其可以管理大量状态(每个分片几G个)
- 容错
集群的一个机器宕机,Samza会利用YARN将job迁移到另一个机器。
- 持久性
Samza利用Kafka保证消息按照写入partition的顺序被消费,并且不会丢失消息。
- 扩展性
Samza的每层都是可扩展的。Kafka提供了按序、分片、可回放、容错的消息流。YARN提供了Samza job运行的分布式环境。
- 可插拔
除了Kafka和YARN,Samza也提供了可插拔的API,与其他消息系统和执行环境结合。
- 处理器分离
Samza利用YARN,可以实现Hadoop的安全模型,以及Linux CGroups的资源隔离。
比较
Stream模型
可以将Samza job的输入和输出当做Stream,Samza的Stream是分片的,分片内有序,可回放,多订阅者,不会丢失的消息序列。Stream还具有缓存的功能,可以隔离各个处理过程。这种Stream模型要求持久化、容错、缓存功能,但其带来的好处很多:
- 下游处理不会阻塞上游处理
Samza的下游处理可以阻塞几分钟甚至几个小时,而不会影响上游处理,这相当于对不同的数据处理阶段进行了解耦。这些处理过程可以是不同的业务进行的,所以这种解耦很重要。
类似于Hadoop中,利用HDFS文件对处理过程进行解耦一样。
在Hadoop中,Map Reduce job的输出就是HDFS文件,其他job的输入也是这些文件,这种思想可以用于构建大型的分布式离线处理系统,Samza的Stream模型相当于将这种模型移植到了分布式实时处理系统。
- 订阅模式
订阅可以让多个job分享一个job的输出,job之间的解耦也可以更容易查找问题。
- 简化框架
每个job只需要关心自己的输入和输出即可,job可以恢复或重启而不会影响其他job,没必要对整个流过程进行控制。
为了实现这种严格的Stream模型,需要将消息写入磁盘,类似MapReduce和HDFS。磁盘也可以提供很高的输入输出吞吐量,以及无限制的磁盘空间,这也是Kafka的基础。
MapReduce的有些job会被认为没有必要写磁盘,MapReduce常用于短时间内处理大量的历史数据(比如一个月),而流式处理一次处理的量级要小很多,比如处理十分钟的数据,其实时性会比较高。
State
只有简单的流处理是无状态的(每次处理一条消息,各个消息之间相互独立)。大多数流处理要求job保存一定的状态。例如:
- 统计与某个用户ID相关的事件数
- 对于某个事件,有多少不同ID的用户浏览过你的网站
- 如果想统计广告点击率,需要将两条流(广告浏览事件和广告点击事件)合并,那么可能需要存储事件,以等待另一条流的对应事件发生。
- 需要与数据库交互时需要获取当前数据库的状态
某些状态,例如计数器(counter),需要保存在job的内存中,如果job重启,状态就会丢失。为了避免这种情况,你会想到将状态存储到数据库中,但是处理每条消息都需要对数据库进行一次查询,而数据库仅能支持1-5k请求/秒,在数据量特别大的情况下,会导致阻塞。而Kafka可以处理100-500k消息/秒(因单条消息大小而异)。
Samza支持高性能、可靠的状态,它会将状态保存在当前节点上(这样就不必经过网络传输),其鲁棒性是靠复制状态到另一条流来保证的。
可以与数据库的change capture功能结合起来。例如,有一条流是带有用户ID的page-view事件,想要扩充这个流,加入与该用户相关的更多信息,你可能会想到查询数据库(或许查询数据库缓存),使用Zamba可以换个思路来解决。
change capture就是每当数据库中的一些数据发生变化时,就会收到关于数据变化的事件。可以将这些事件发送到changlog流中,在本地节点对其进行消费,每当有新的change发生时,就将其存入本地节点。这样有page-view事件到达时,就可以查询本地而非远程数据库(如果对数据库实时性没有难么高要求的话可以这么做)。
当然对数据库的写入操作还是直接对数据库操作。只有查询对本地节点操作即可。
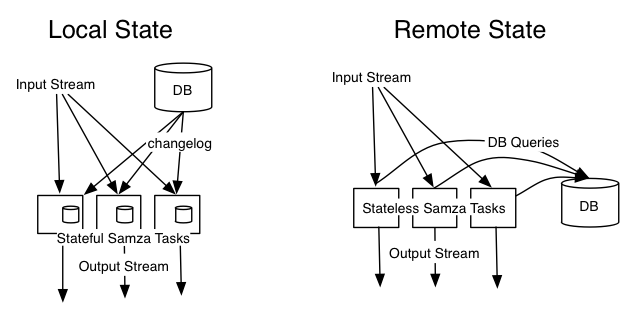
这种本地化也减少了对远程数据库的查询压力,避免了对其他服务的影响。当然Samza并没有禁止访问远程数据库,这种本地化主要看业务需求,如果觉得本地数据并不是很可靠,也可以直接查询远程数据库。
执行框架
Samza并没有构建自己的分布式执行系统,而是依赖YARN。
-
执行框架YARN已经很完善 支持资源配额和安全,可以决定集群的哪个部分分配给哪个user和group,也可以通过groups控制节点的资源(CPU、内存等)
-
与YARN的组合是完全组件化的
Samza构建并不依赖YARN,可以替换成其他虚拟化框架,例如直接集成AWS,与使用YARN的目的一样,可以创建和销毁容器。与其在AWS上运行YARN,不如直接为job分配EC2实例。
所以Samza更倾向于与Mesos、YARN、amazon等结合。